The Design Philosophy of BookHive



This is a write up of the talk that I did at ATmosphereConf 2026 in Vancouver on March 29th, 2026. You can watch the presentation here:

The Opportunity
What ATProto represents is a trend reversal, the web started as open, and became progressively more closed down. There has been multiple attempts of this, but none have garnered this much traction, let’s leverage it!
- Social Networks, in particular, have become data silos
- If you don’t pay for it, you are the product
- User agency is at an all-time low, users are forced through upgrades, with no other recourse
- Closing down of APIs, especially with AI, data is seen as a moat
But, of course that is part of why you are all here, to see an open web, based on user agency. I think we often forget that the web came with this idea of a user-agent, allowing users to customize their experience according to their needs. It largely didn’t pan out because of the complexity of sharing data, it naturally led to the rise of locked down APIs.
BookHive
BookHive is an open source, open data alternative to Goodreads. You can track your books, organize your shelves and connect with others who read the same books as you.

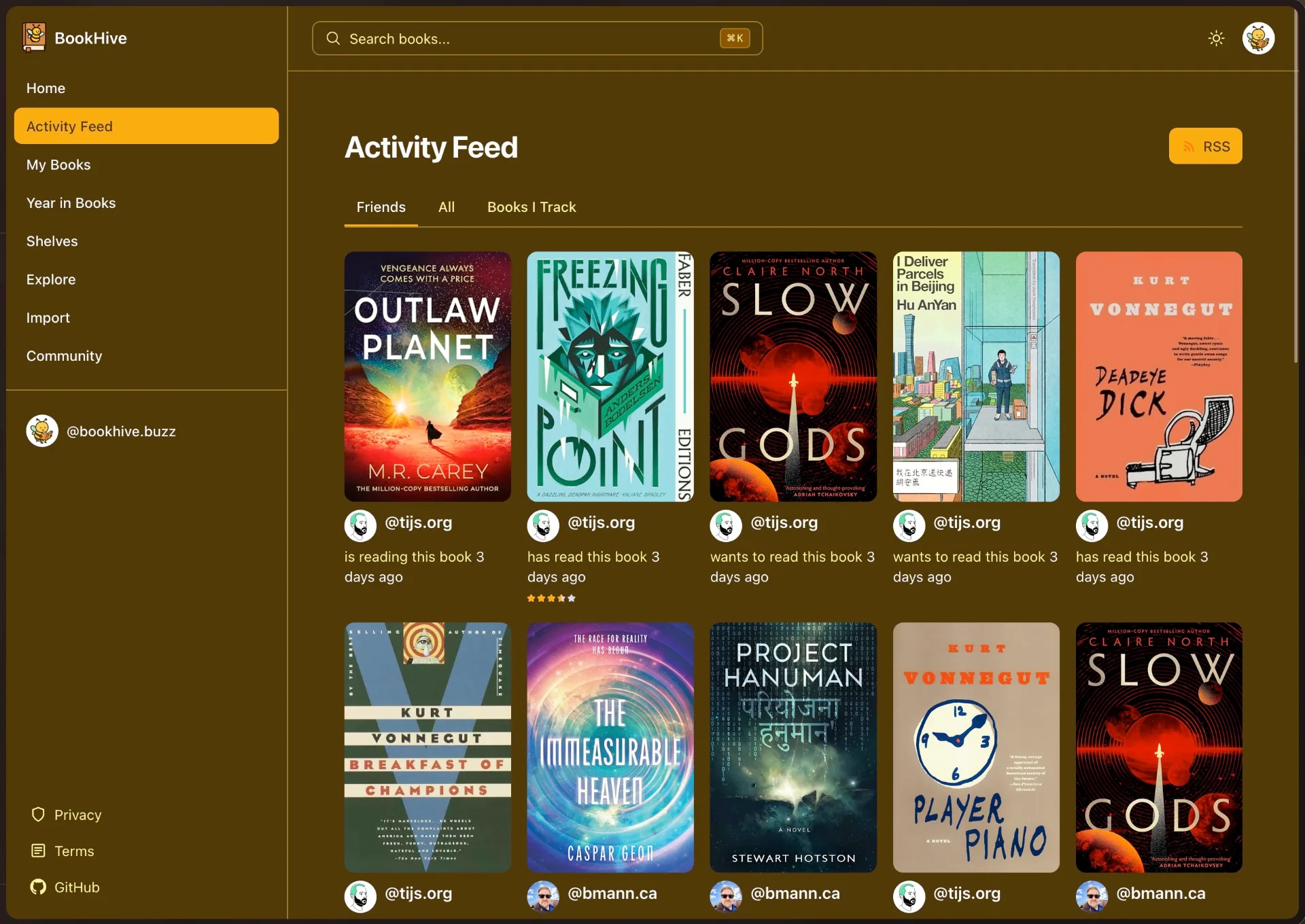
When building BookHive, my thinking was all about storing the maximally useful data in the user’s PDS. This means, data the user & other applications can leverage to be in service of the user.
The PDS is not just a database
If you think about what would be needed to store the data for BookHive, all that you really would need is some sort of identifier for the book, the user's status (reading, read, want to read), and some timestamps. That is the minimal representation of the book, and often what you'd find stored in a database for this sort of application. But, ATProto should not be about the minimal it should be about the maximally useful representation. It is the user's data, give everything that you can to them, to provide them with agency over that data.
We have an opportunity to build social software where the data actually belongs to people: let's not waste it by storing opaque identifiers. The PDS should not be treated just as some datastore, it is more than that, it should be an interface of user-agency. Everything you provide the user gives them more freedom, so give them all you can!
A thought experiment: If BookHive disappeared tomorrow, is the data in your PDS still meaningful?
Yes, you will have everything you need to display a book’s data; especially, now that we have “catalogs"

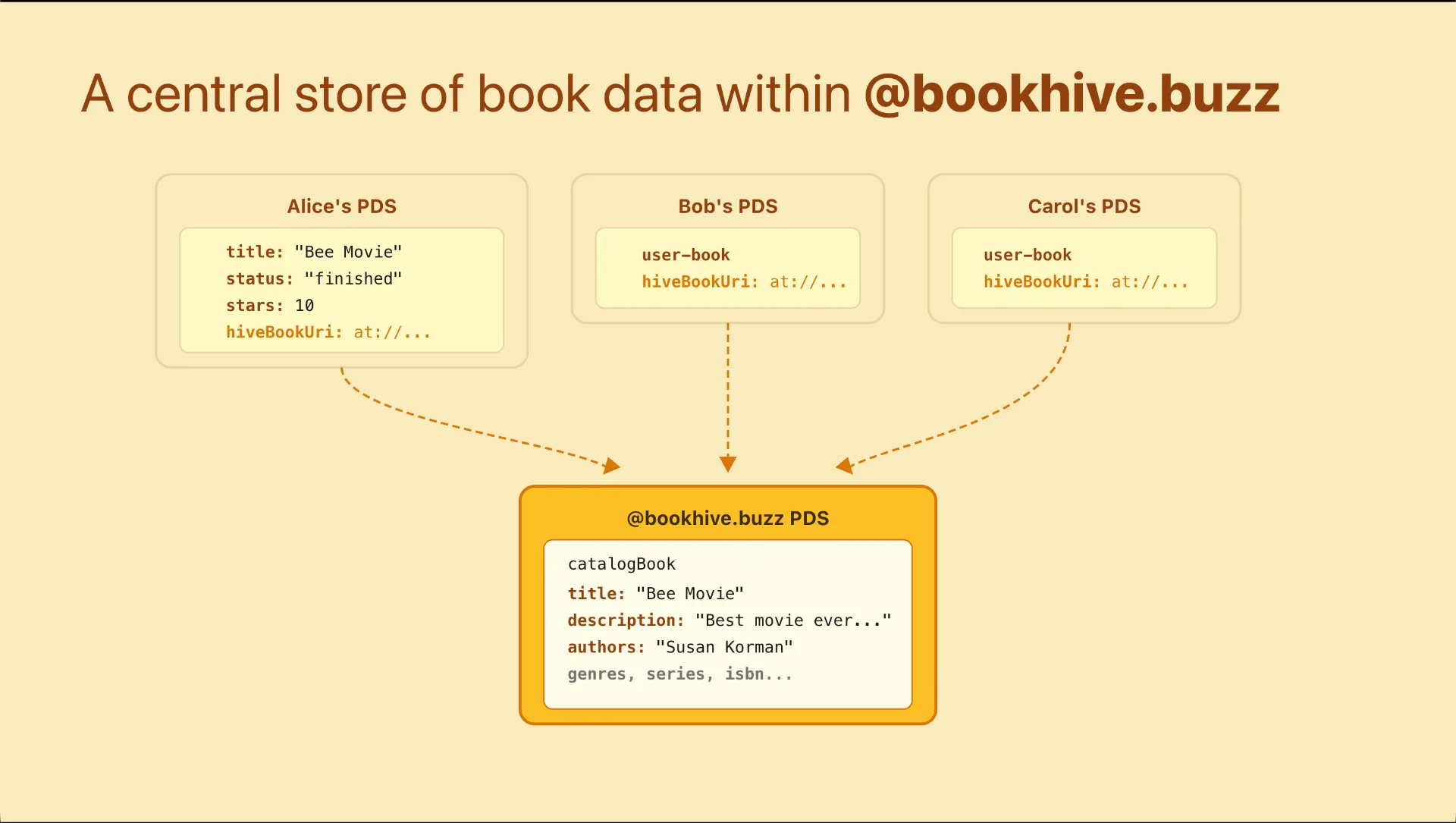
A catalog is a central store of book data under the @bookhive.buzz service account. This means all book data is on-protocol, everything on BookHive can be reconstructed purely from data available within the network. This works by leveraging a URI to point from a user's book record to the @bookhive.buzz catalog book through a hiveBookUri
Proof that the open-data, open-source approach works:
Popfeed.social can interoperate with our lexicon, because all of the data is already in the user’s PDS, fully self-contained

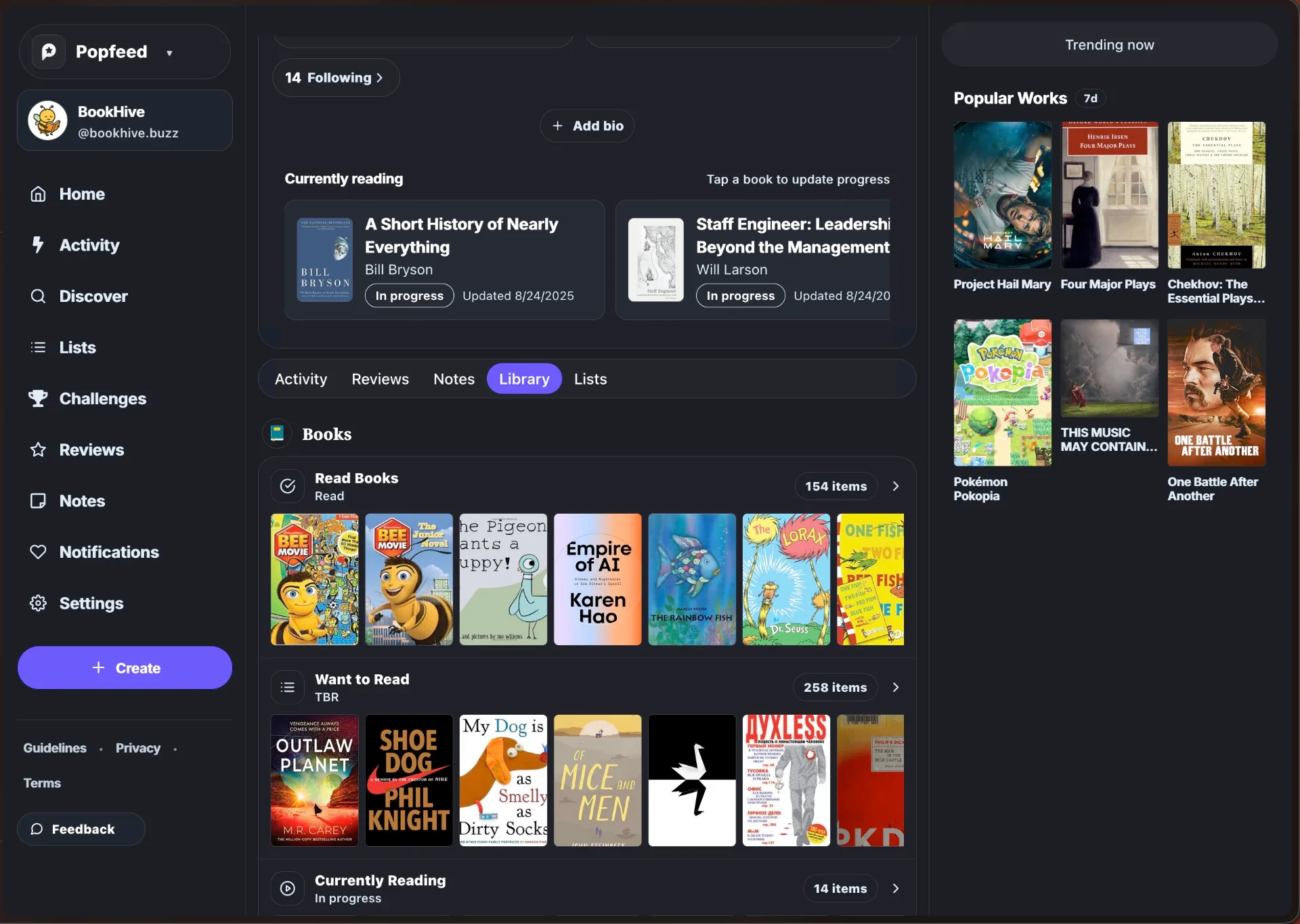
Users are able to display their library on personal websites, without any interaction with BookHive APIs. Like Tijs Teulings 🦑 was able to make a completely alternative frontend for managing BookHive books.

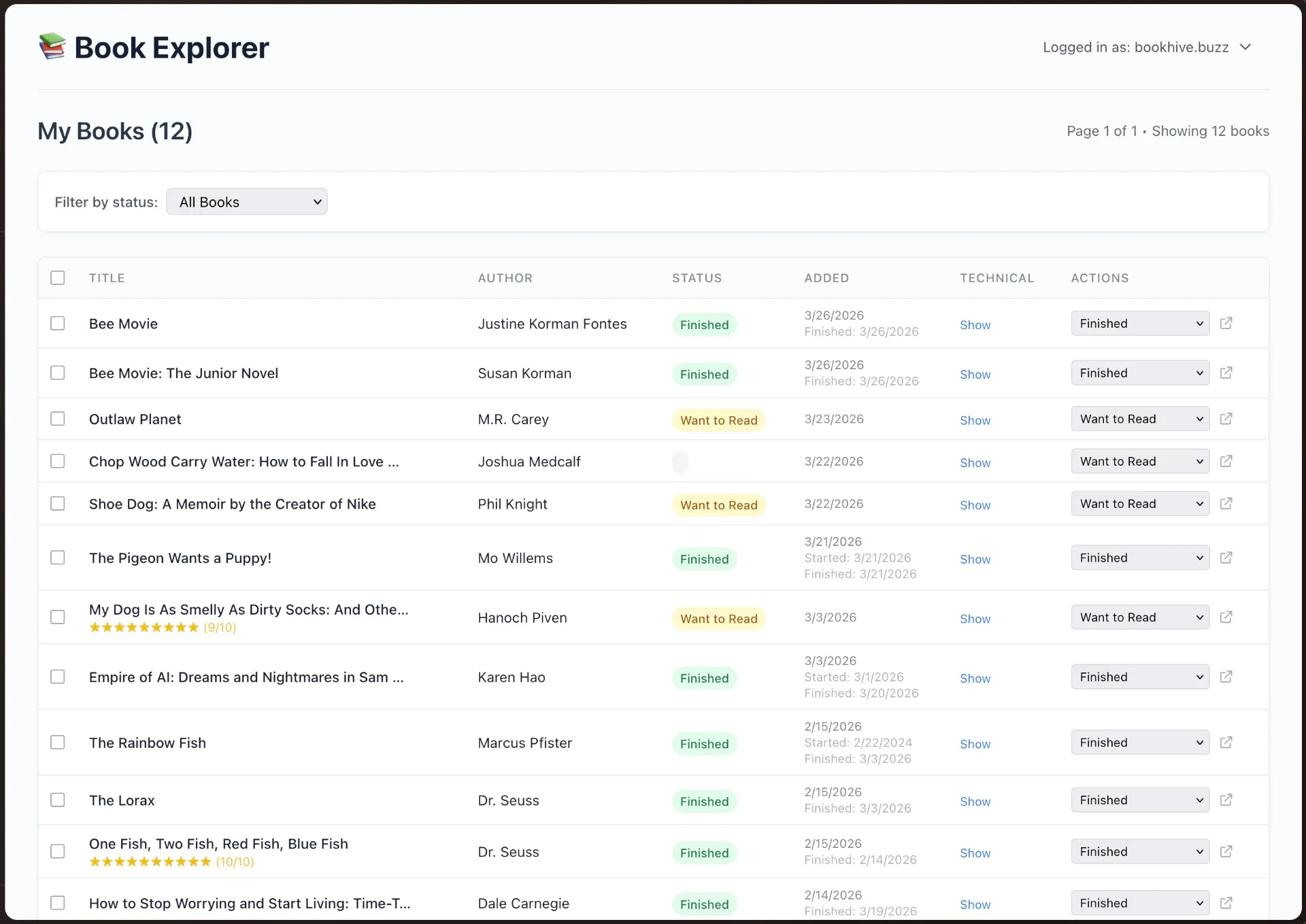
This only works because BookHive stores the maximally useful data in service of the user.
Takeaways for Builders
- Store what's useful to the user, not just what's useful to you. Include enough context that the record is self-describing. The PDS is not just a database.
- Use standard identifiers. Publish open datasets on-protocol. ISBNs, DOIs, URLs -- anything that lets other apps cross-reference. It's actually very hard to get a good book dataset. Your enrichment work can benefit everyone.
- The "day after" test. If your service shuts down tomorrow, is the user's PDS data still valuable? If not, rethink what you're storing.
Closing statements
Empower Users
Be their agent
Open Data
Open Source

Sign in to leave a note.